SceneVGGT: VGGT-based online 3D semantic SLAM for indoor scene understanding and navigation
SceneVGGT is a spatio-temporal 3D scene understanding framework that combines SLAM with semantic mapping for autonomous and assistive navigation. It supports online, real-time processing of streamed data (e.g., from an iPhone Pro). The pipeline’s GPU memory usage remains under 17 GB, irrespective of sequence length, and achieves competitive point-cloud performance on the ScanNet++ benchmark. Overall, SceneVGGT ensures robust semantic identification and is fast enough to support interactive assistive navigation with audio feedback.
Overview
SceneVGGT enables temporally coherent 3D semantic mapping by lifting 2D instance masks into 3D and tracking instances with the VGGT tracking head. Persistent object identities + timestamps provide computationally efficient, temporally consistent change detection, while floor-plane projection of object locations supports downstream assistive navigation—including a proof-of-concept navigation module.
3D semantic SLAM and navigation from Streaming Inputs

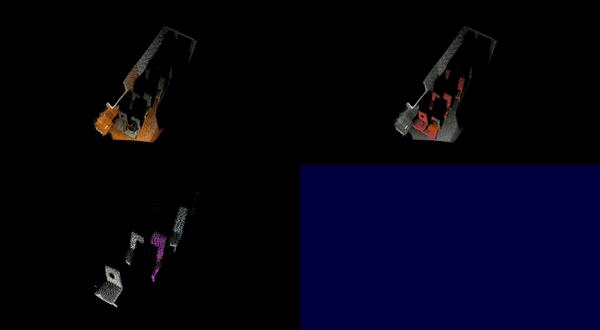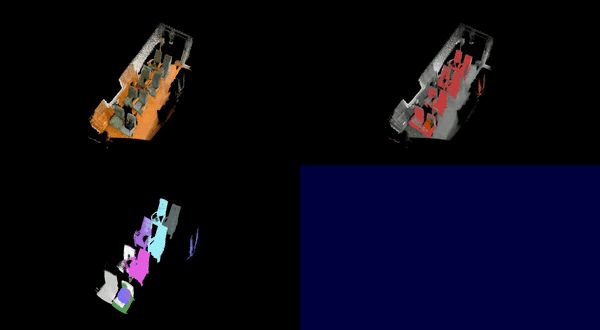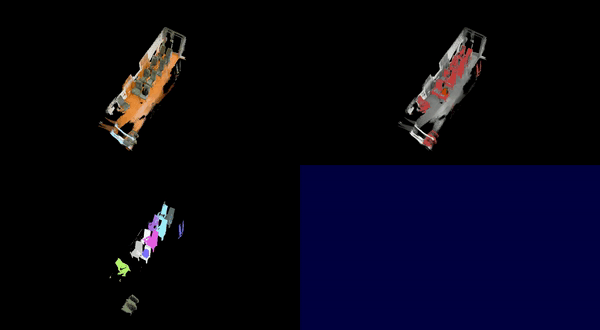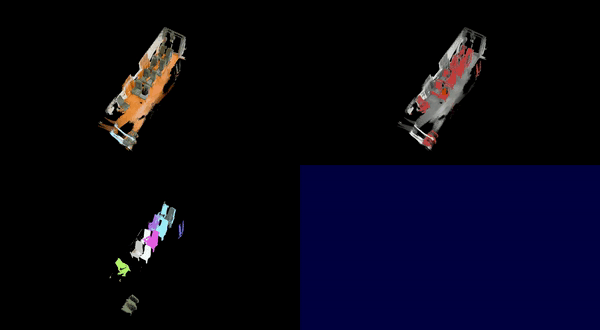
Additional visualized results on the ScanNet++ dataset are available in this YouTube playlist .
Installation
- Clone SceneVGGT
git clone git@github.com:HBVC-AI/SceneVGGT.git
cd SceneGGT- Create conda environment
conda create -n scenevggt python=3.10
conda activate SceneVGGT- Install requirements
pip install -r requirements.txtCitation
If you find this project helpful, please cite the following paper:
@article{scenevggt,
title={SceneVGGT: VGGT-based Online 3D Semantic SLAM for Indoor Scene Understanding and Navigation},
author={Anna Gelencsér-Horváth, Gergely Dinya, Dorka Boglárka Erős, Péter Halász, Islam Muhammad Muqsit, Kristóf Karacs},
year={2026},
eprint={2602.15899},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.15899},
}